
어제 한 거랑 똑같이 스파르타플릭스도 db연결한다
DB에 저장
$("#postingbtn").click(async function () {
let image = $('#image').val();
let title = $('#title').val();
let comment = $('#comment').val();
let stars = $('#stars').val();
let doc = {
'image': image,
'title': title,
'stars': stars,
'comment': comment
}
await addDoc(collection(db, "movies"), doc);
window.location.reload();
})
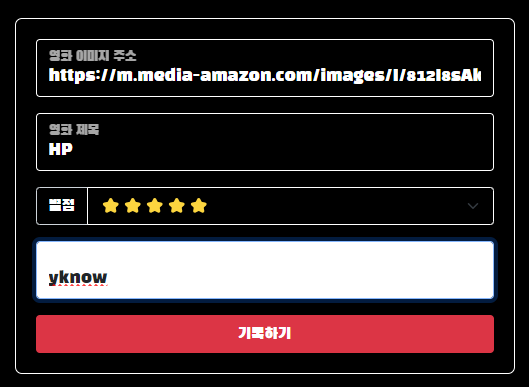

잘 들어가는 모습을 확인할 수 있다
DB에서 불러오기
let docs = await getDocs(collection(db, "movies"));
docs.forEach((doc) => {
let row = doc.data();
console.log(row);
let image = row['image'];
let title = row['title'];
let comment = row['comment'];
let stars = row['stars'];
let temp = `
<div class="col">
<div class="card">
<img src=${image}
class="card-img-top" alt="...">
<div class="card-body">
<h5 class="card-title">${title}</h5>
<p class="card-text">${stars}</p>
<p class="card-text">${comment}</p>
</div>
</div>`;
$('#cards').append(temp)
});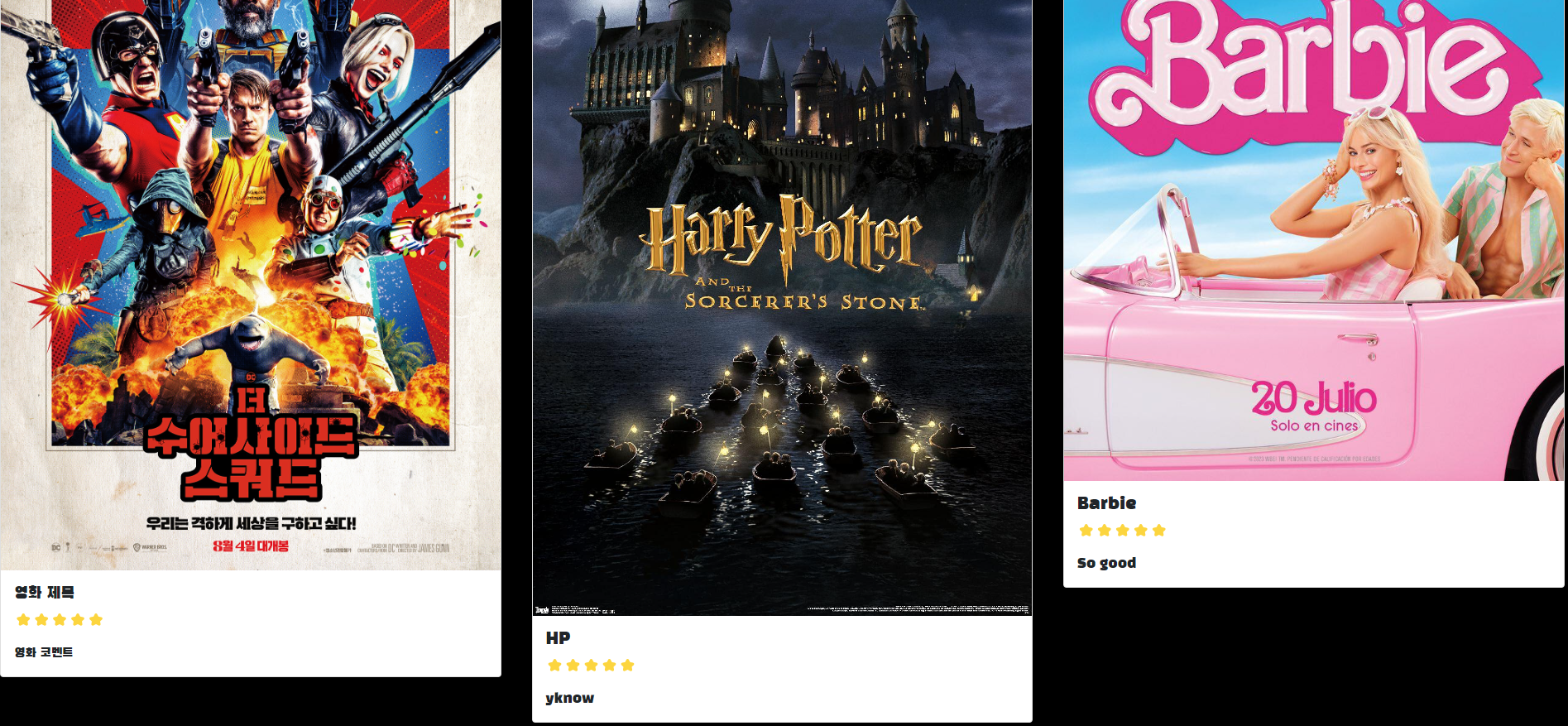
새로고침하면 잘 불러와짐!
배포
github 가입 후 스파르타플릭스를 올려본다
그리고 settings ->pages -> branch를 main으로 바꿔준다
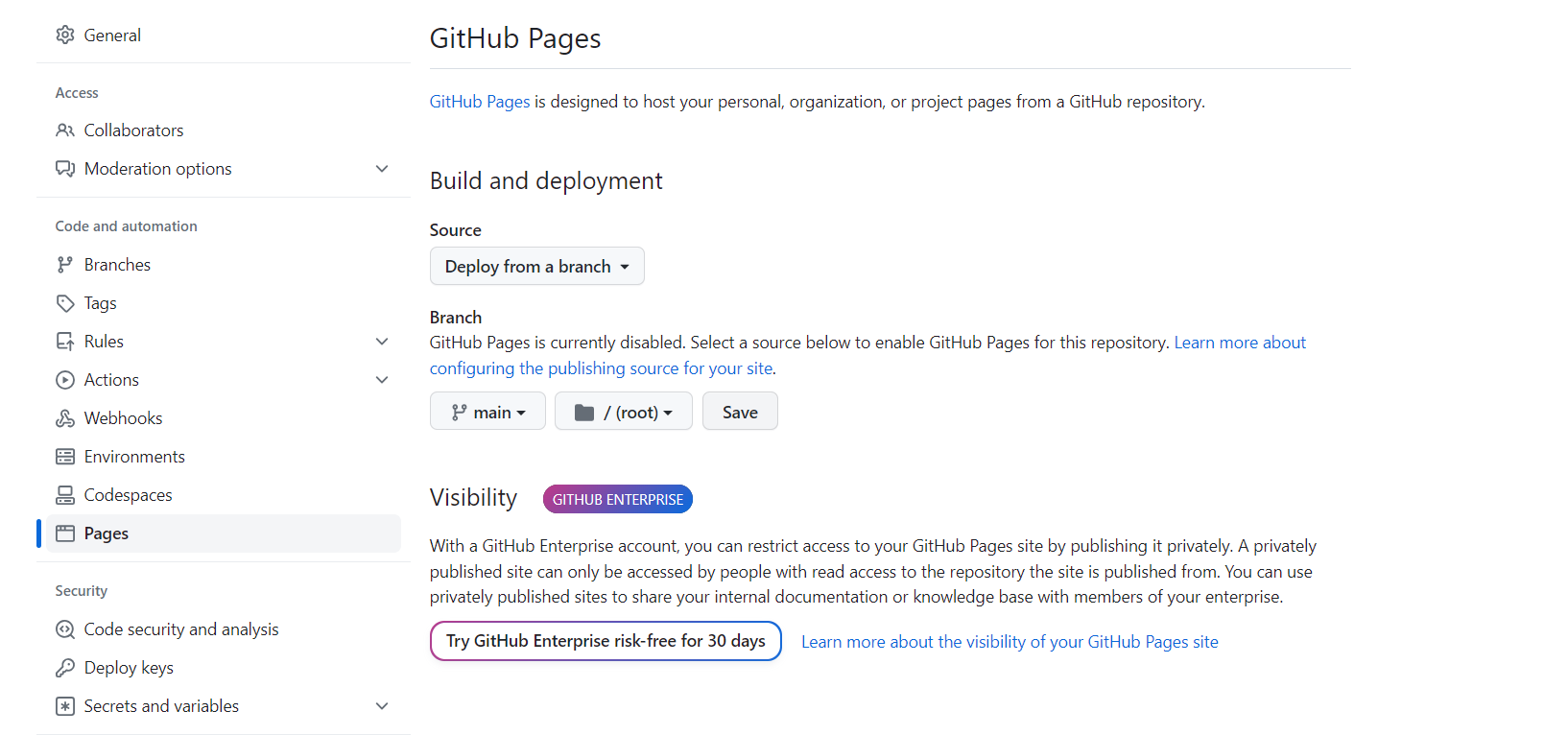
save누르고 새로고침하면 visit site가 뜬다
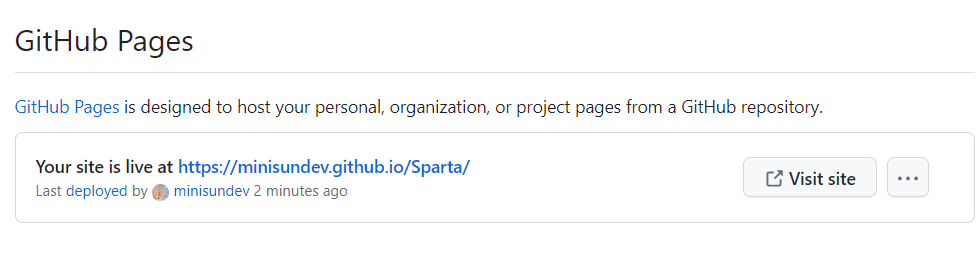
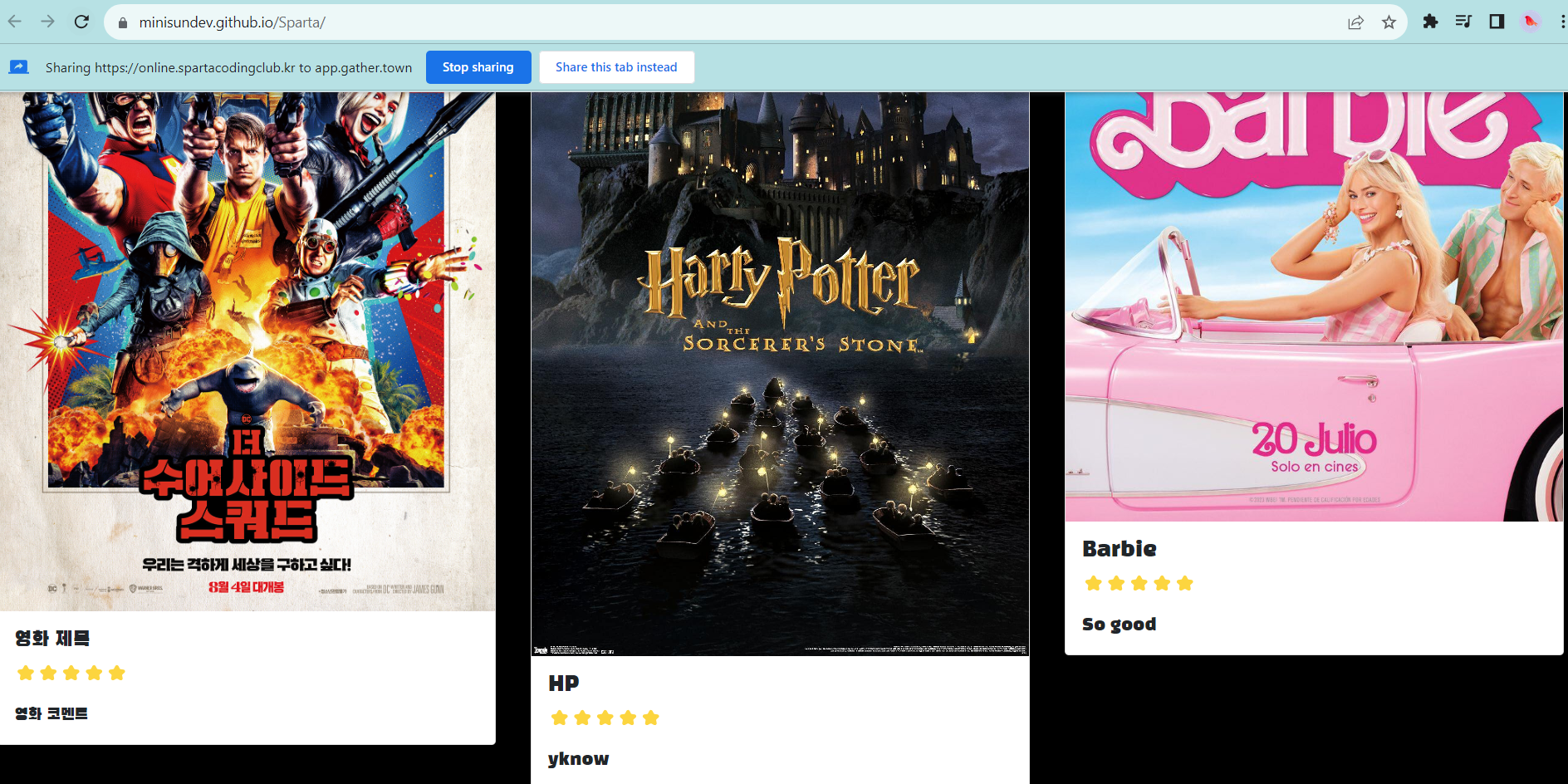
아까 db에 넣어놓은 거 잘 뜸
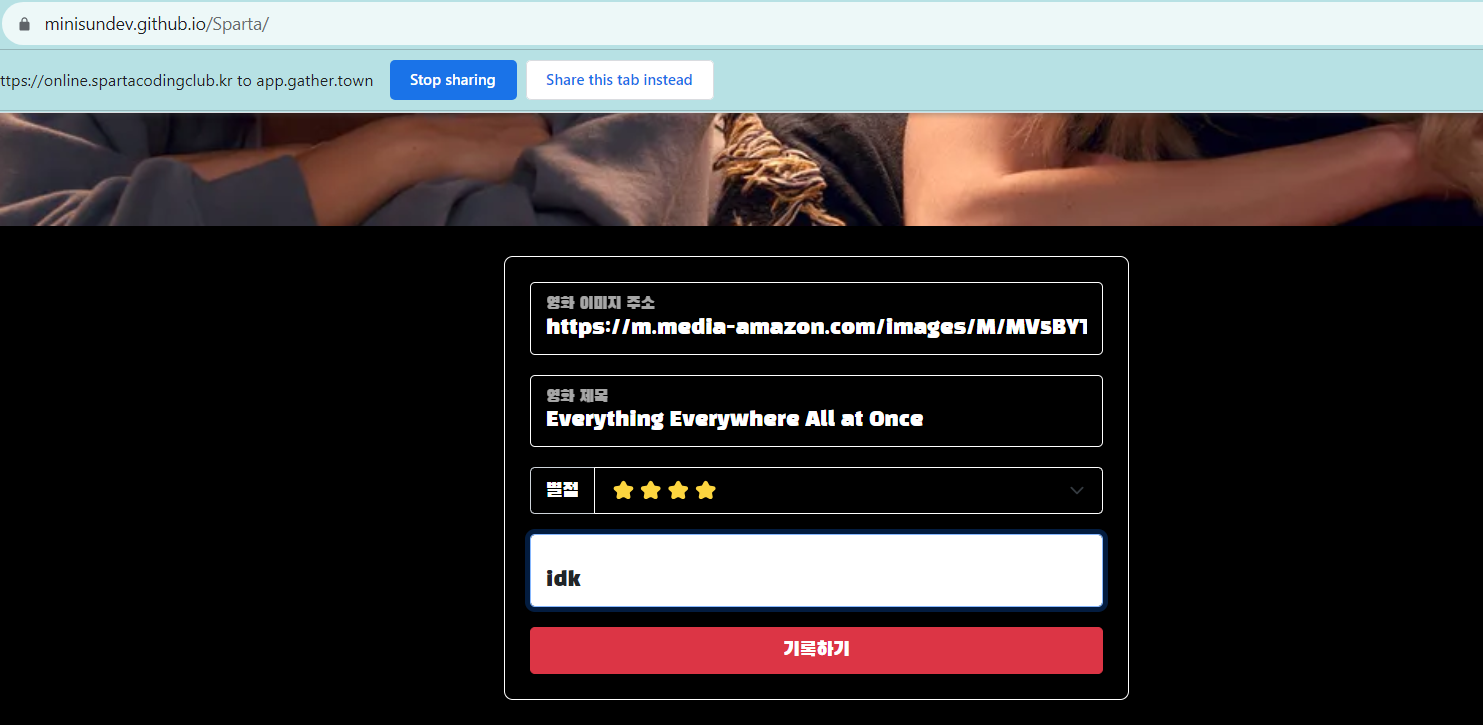
하나 더 넣어본다

잘 들어가고 잘 뜬다
웹 스크래핑 맛보기
https://colab.research.google.com/
Google Colaboratory
colab.research.google.com
접속하여 새 파일을 만듦
https://movie.daum.net/ranking/reservation
랭킹 | 다음영화
Daum영화에서 자세한 내용을 확인하세요!
movie.daum.net
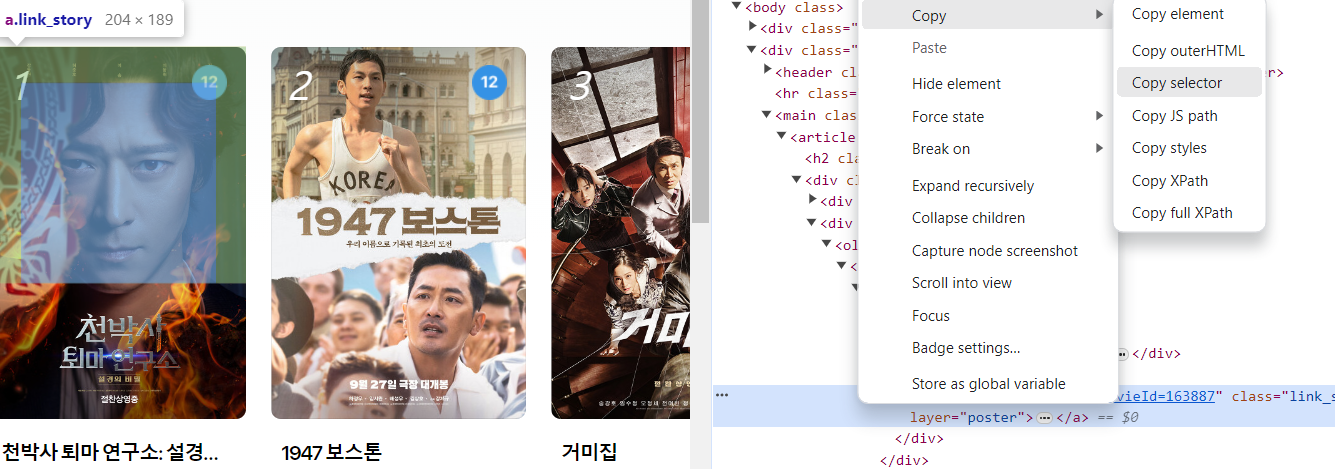
영화 우클릭 -> 검사 -> 해당 항목 우클릭 -> copy -> copy selector
import requests
from bs4 import BeautifulSoup
URL = "https://movie.daum.net/ranking/reservation"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
title = soup.select_one('#mainContent > div > div.box_ranking > ol > li:nth-child(1) > div > div.thumb_cont > strong > a')
print(title.text)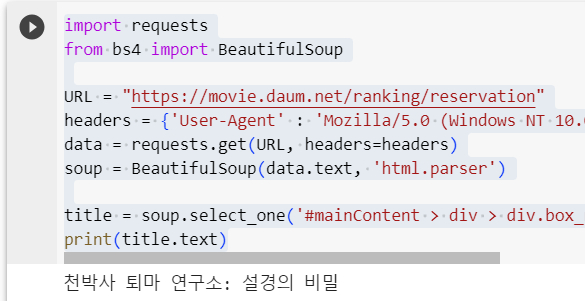
이렇게 뜬다 랭킹별로 이미지까지 다 긁어오기도 가능하다
'Developing > TIL(Develop)' 카테고리의 다른 글
| 첫 실습! HelloWorld GET해오기 with SpringBoot + Postman (1) | 2023.11.01 |
|---|---|
| Spring 입문 (1) | 2023.10.31 |
| 스파르타코딩클럽 사전캠프 4주차 Firebase 연결 (0) | 2023.09.25 |
| 스파르타코딩클럽 사전캠프 3주차 JQuery + fetch (0) | 2023.09.19 |
| 스파르타코딩클럽 사전캠프 2-3주차 JQuery (0) | 2023.09.14 |


